Mustafa Al-Salem
Canada
I’m an engineer with 3+ years of experience building and validating reliable software systems, with strengths in quality engineering, Java automation, API testing, and system-level/firmware validation. I’ve worked in environments where correctness and stability matter using rigorous testing strategies, clear debugging, and strong attention to detail.
Recently, I’ve expanded into data engineering and machine learning, working across the pipeline from data ingestion and preprocessing to model training, evaluation, and deployment. I’m especially interested in production ready ML systems that pair scalable data pipelines with well measured model performance, particularly in cloud and healthcare contexts. I bring an analytical mindset, a focus on reliability and reproducibility, and a drive to ship systems that work in the real world.


Certifications
- AWS Certified Cloud Practitioner (In Progress)
Projects

Resume on Cloud
Deployed a serverless portfolio using AWS Lambda, API Gateway, and DynamoDB, fronted by CloudFront with HTTPS and custom domain routing.
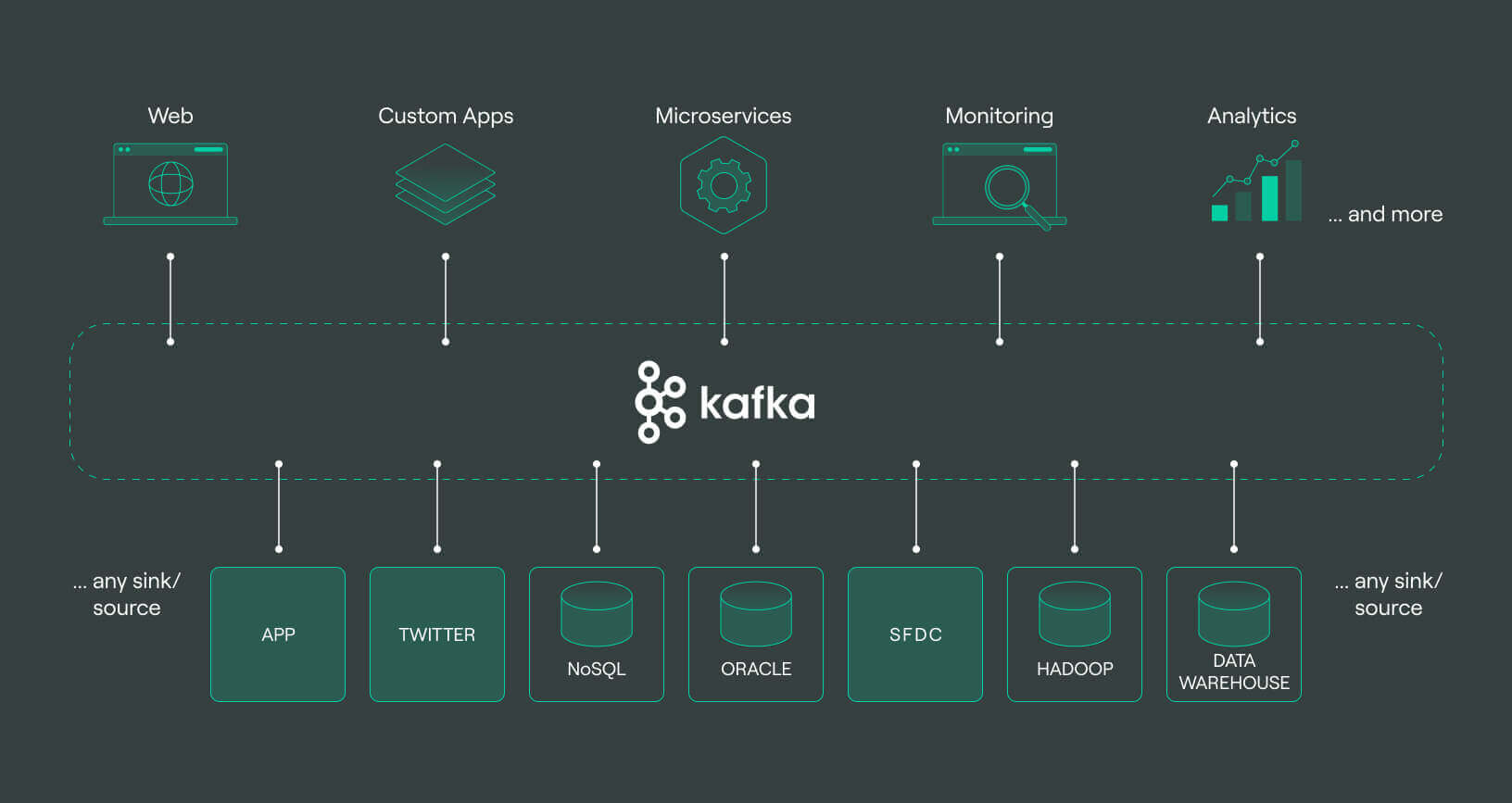
Stock Market Kafka Pipeline
Designed a real-time Kafka pipeline for stock data ingestion and processing, integrating AWS services for scalable storage and downstream analytics.
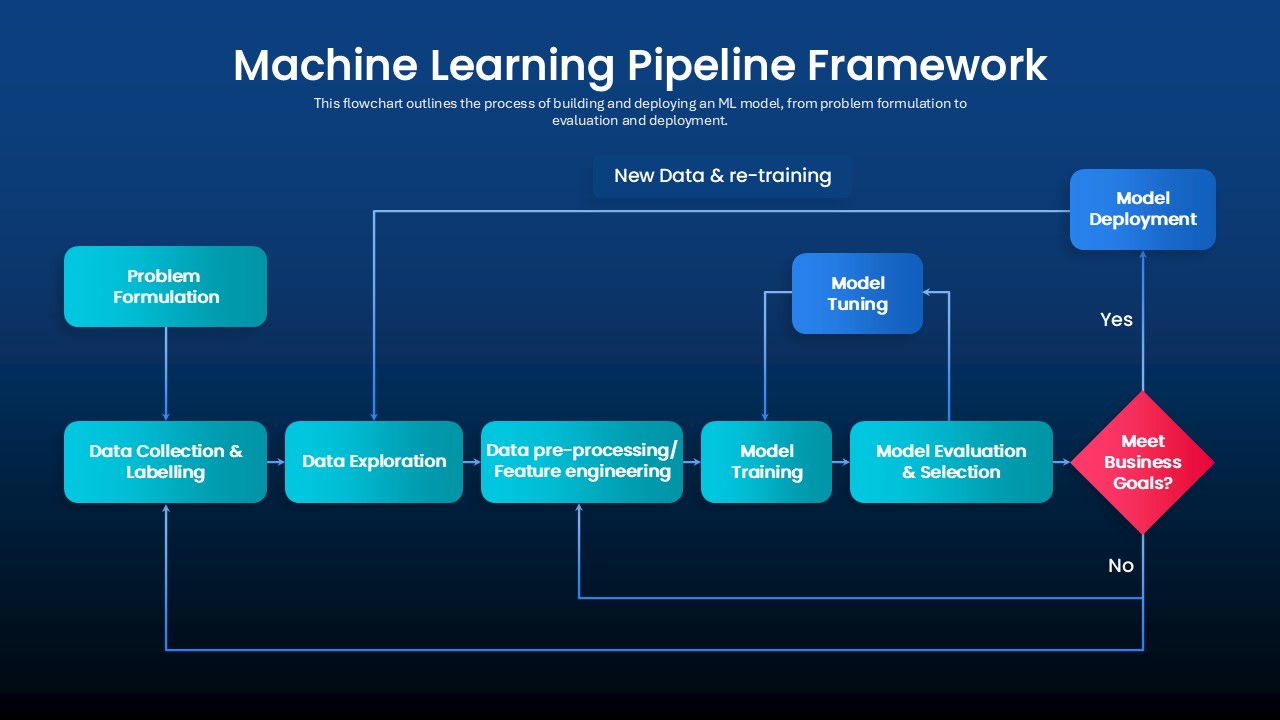
ML Mortality Prediction
Designed an end-to-end pipeline to ingest, preprocess, and model ICU time-series data from MIMIC-III using RNN and GNN architectures, achieving improved AUC while maintaining reproducible training and evaluation.
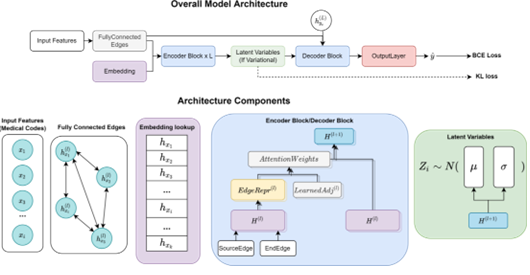
GNN Clinical Risk Prediction
Replicated and extended a Variationally Regularized GNN for patient risk modeling using EHR graphs, addressing sparsity and scalability issues in large clinical datasets.
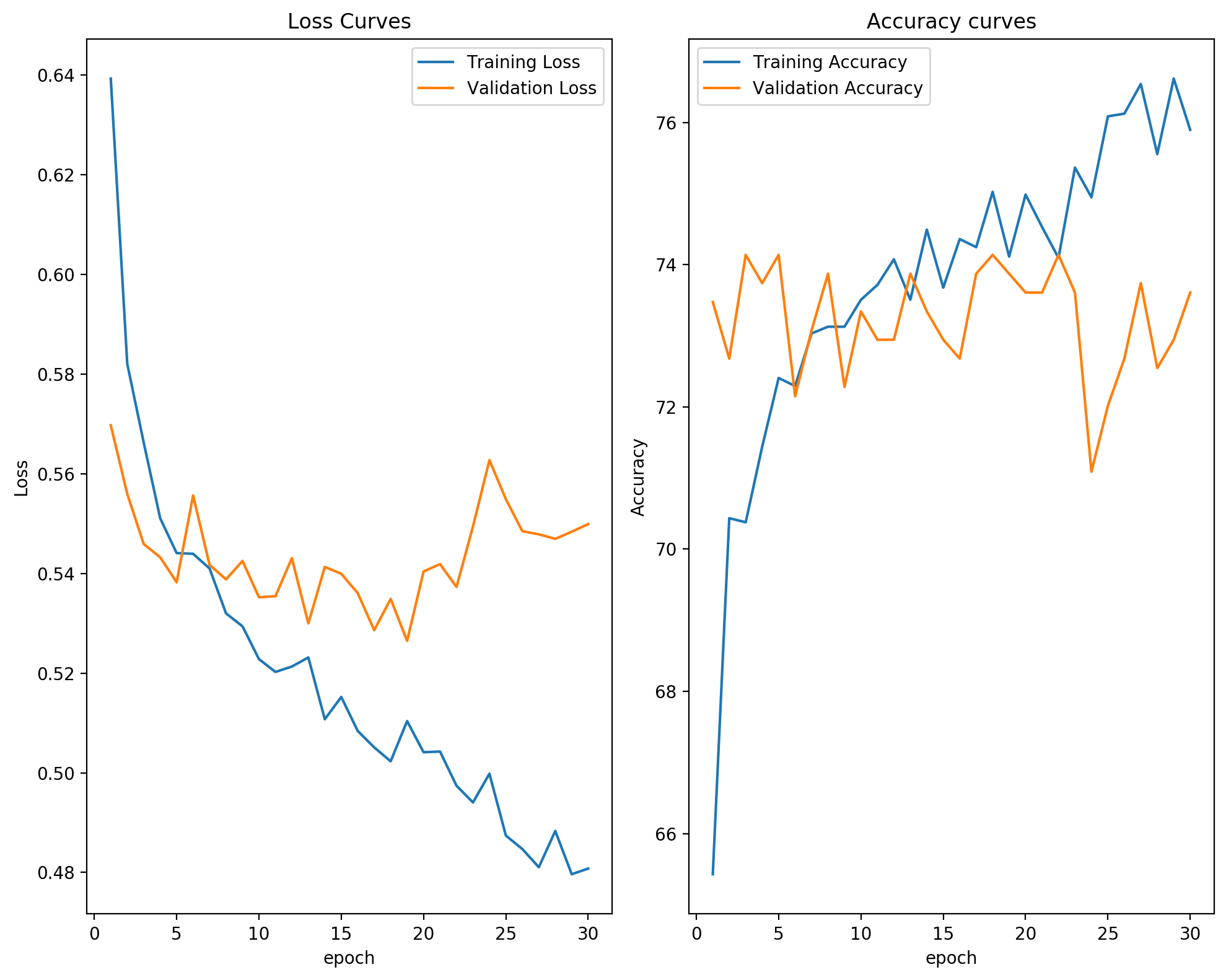
RNN Mortality Prediction
Built a PyTorch RNN pipeline for ICU mortality prediction using time-series vitals, with custom DataLoader and reproducible training achieving competitive AUC on MIMIC-III.